Anthony Wells, who has been doing a marvellous job of plugging my political survey, expresses a little confusion about what its preliminary results mean. This is fair enough, since there's basically no explanation on that page. So as a public service, I'll tell you all about it....
For those of you who haven't done the survey or something like it, the first thing to say is, go and do it now -- doing so will make me very happy. (OK. A little bit happy. Whatever.) The second thing to say is that the survey consists of a list of `statements' (loosely, I refer to these as `questions'). Each statement is presented as a proposition, and respondents are asked whether they agree with each statement, `as [it] would apply to the country where [they] live'. Implicitly the statements describe policies or something like them: possible courses of action or ideas which should inform decisions by governments or citizens.
So, each statement gets a response, like this:
| Response | Value |
|---|---|
| Disagree strongly | -2 |
| Disagree | -1 |
| No opinion | 0 |
| Agree | +1 |
| Agree strongly | +2 |
(Note that there's an ambiguity here, between disinterest and uninterest. Ignore that.)
Now, one problem with a survey like this is that the way each proposition is phrased will influence its results. So the propositions all have two forms, which are supposed to be the converse of one another, for instance,
| Normal | Converse |
|---|---|
| Sometimes interest rates should be raised to reduce inflation, even if doing so would cause a large number of job losses. | It's not worth raising interest rates to reduce inflation if this would result in the loss of large numbers of jobs. |
| Overall, economic migrants bring benefits to our country. | Overall, economic migrants are a drain on our country. |
| Anybody who wants top-quality health care should expect to have to pay for it. | Everybody has a right to top-quality health care, even if they aren't wealthy. |
(Note that the terms `normal' and `converse' don't carry value judgements; they are just terms. The two forms of each statement could be labelled `a' and `b' instead; it wouldn't make any difference.)
You can also look at the full list of statements, but please take the survey first.
Each respondent to the questionnaire is given every available statement, in one of its two forms. A few of these statements are then repeated in the other form at the end of the survey. The pairs of answers to the two forms of the same question can then be compared, to see whether those who agree with one form necessarily disagree with the other. This is what the set of graphs at the top of the preliminary results are about. An example:
| Normal | Converse |
|---|---|
| New roads and railways should be built by private companies, not the government. | New roads and railways should be built by the government, not private companies. |
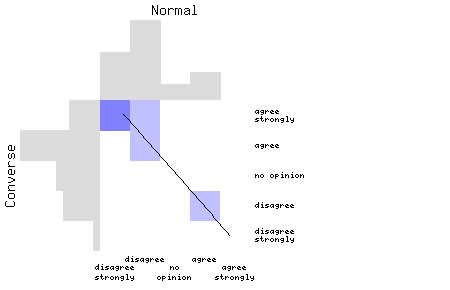
The grey bars at top and left show the distribution of answers to the two forms of the question. Bigger bars mean more answers. So, most people disagreed with the `normal' form, and agreed with the `converse' form -- in both cases, thinking that transport infrastructure is the job of the state. (This probably reflects the political biases of my friends. Anthony's Tory readers, if they complete the survey in sufficient numbers, may swing the pendulum back again.)
The blue boxes show the responses of people who answered both forms of the question. Darker shades mean more people. In this case, two people disagreed strongly with the `normal' version, and agreed strongly with the `converse' form; and one each in the other combinations. Of note is the one respondent who disagreed with the `normal' form, but agreed strongly with the `converse form'.
The black line shows a best-fit line through the pairs of answers. Later on, the analysis relies on being able to turn the `converse' answers into `normal' answers, and this line is used to do it. In this case it tells us that somebody who agrees strongly with the `converse' statement would probably have answered somewhere between disagree strongly and disagree to the `normal' statement. The fact that the line goes from top left to bottom right is a Good Thing, since it indicates that the two statements are good antonyms.
Here's another example:
| Normal | Converse |
|---|---|
| National law should always override international agreements. | Sometimes international agreements should override national law. |
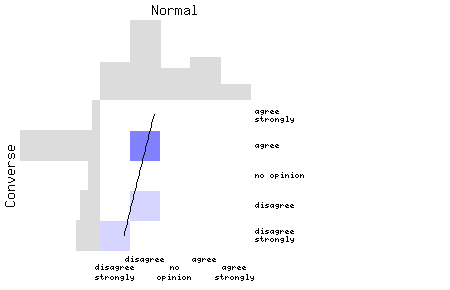
Here, there are a number of people who disagree with both forms of the statement. Arguably a contradiction, this probably means that the statements could be worded more clearly. It's worth noting that (a) we have only four pairs of points on this plot, which is not really enough to reach any secure conclusions; (b) the two distributions (grey bars) do appear to be the converse of one another, sort of: lots of people disagree with the `normal' statement, and agree with the `converse' statement, which is good. Nevertheless, the fact that the best-fit line goes from bottom left to top right is a Bad Thing, and suggests that this statement may not be a good one.
Next we come to the most and least correlated statement pairs.
What's going on here is that we look at all the responses to each pair of statements (mapping `converse' onto `normal' using the best-fit lines, as above), and see how the answers to the pairs of statements are related to one another. The column marked `Cov' is the covariance in the responses; MathWorld has the gory details, but basically,
- if the number is about zero, the two statements aren't related to one another;
- if the number is positive, then somebody who agrees with the first statement is also likely to agree to the second;
- whereas, if the number is negative, then somebody who agrees with the first statement is likely to disagree with the second.
So, for instance, somebody who agrees that `Drug abuse is a problem primarily because of its effects on drug users, not its effects on the rest of society' is likely to disagree that `Our armed forces should intervene to stop genocide in other countries'; whereas, somebody who thinks that `Some crimes are so serious that the only proper punishment is the death penalty' is likely also to think that `Anybody who wants top-quality health care should expect to have to pay for it'.
(It's worth noting that there really aren't enough results to draw any useful conclusions from this, yet. But these results are encouraging, in the sense that they agree with widely-held stereotypes.)
On the `not at all related' side, we discover that peoples' views on whether `Aid projects abroad should always be funded by charities, not the taxpayer' are basically unrelated to whether they think that `Smokers should be required to kick the habit before receiving medical care for smoking-related illnesses'; and believing that `Correct grammar is important' is unrelated to thinking that `Everyone should have the right to trial by jury'.
Next comes the real meat of the survey.
Having collected a large number of sets of responses, we want to pick out combinations of statements which characterise particular views. As a pedagogical example, the traditional left -- right axis might be characterised (or, perhaps more accurately, caricatured) by agreement with a combination of statements like,
- New roads and railways should be built by private companies, not the government.
- Services like health care, education and social security should be provided by private enterprise, not by the government.
- Children should always obey their parents.
- Aggressive foreign policies can put a stop to international terrorism.
- The wealthy shouldn't pay a larger proportion of their income in tax than the poor.
- Overall, economic migrants are a drain on our country.
But the point of this survey is to pick the combinations of statements which characterise peoples' views automatically, or, rather, without the intervention of human prejudice.
A classical statistical technique for this is called principal components analysis. I refer to a good summary in my notes about the survey methodology, but basically all you need to know is that this procedure picks out combinations -- called `eigenvectors' -- of statements which correspond to the greatest spread (in fact, variance) among the respondents. (If you're happy to imagine a sixty-something dimensional space, the eigenvectors describe the axes -- the longest dimensions -- of the cloud of points in that space which represent the responses to the questionnaire. There's a two-dimensional example in the summary I link to above, which is probably easier to visualise....)
Each eigenvector consists of a list of statements and numbers. The numbers say how important the statement is in determining where a respondent lies along the eigenvector; a positive number means that agreeing with the statement pushes you further along the eigenvector; a negative number means that disagreeing does. The various eigenvectors are independent (strictly, `orthogonal'), meaning that moving along one of them doesn't affect your position on the others.
The eigenvectors are listed in order of their importance. So, for instance, the most important one -- the one which explains the largest part of the variation among the responses -- starts with,
| Value | Statement | Sense |
|---|---|---|
| -0.278684 | It's more important to rehabilitate criminals than to punish them. | disagree |
| +0.271630 | Some crimes are so serious that the only proper punishment is the death penalty. | agree |
| +0.266926 | Some people should not have access to the Internet. | agree |
| +0.227868 | Aggressive foreign policies can put a stop to international terrorism. | agree |
| -0.223052 | Services like health care, education and social security should be provided by the government, not by private enterprise. | disagree |
| +0.209522 | Anybody who wants top-quality health care should expect to have to pay for it. | agree |
| -0.191752 | Our armed forces should intervene to stop genocide in other countries. | agree |
| -0.186817 | The mix of minorities in public institutions should reflect their numbers in the general population. | disagree |
So, a person who believes in severely punishing criminals (executing some of them), leaving some people without access to the `Information Superhighway', privatising the NHS, leaving people in the third world to stew in their own juices and who doesn't like affirmative action would be at the extreme end of this axis. Naively we might say that this axis is about authoritarianism, belief in the supremacy of the nation state and in market capitalism.
The next most important axis starts,
| Value | Statement | Sense |
|---|---|---|
| +0.423295 | Our armed forces should intervene to stop genocide in other countries. | agree |
| +0.257066 | Scientists bear no moral responsibility for how their discoveries are used. | agree |
| +0.242227 | Dealing with nuisance crimes like petty vandalism makes serious crime less likely. | agree |
| -0.238125 | Some technologies should never be used, whatever their benefits. | disagree |
| -0.233065 | There are some sexual acts which are immoral, even between consenting adults. | disagree |
| -0.217044 | Shared religious beliefs should be an important part of our society. | disagree |
| +0.184733 | Sometimes civilians are a legitimate military target. | agree |
| -0.184652 | To protect society from drug abuse, narcotics must be banned. | disagree |
Here, a person who believes in intervening to stop genocide abroad (apparently sometimes bombing civilians to do so...), the effectiveness of `zero tolerance' policing, the `Feynmann principle' (that scientific discovery and social responsibility are decoupled), legalising drugs and allowing people to do what they like in bed, and who doesn't believe in god will wind up at the extreme end of this axis. It's harder to say what this axis `means', but some of the issues can be identified with traditional social liberalism.
I'll repeat that we don't have enough data to say anything very useful about these yet. These results probably tell us a reasonable amount about my friends and others they've told about the survey, but not about the population at large.
Nevertheless, the formation of the first two eigenvectors is quite interesting. In particular, the axes don't in any way resemble the `economic' and `social' axes imposed by the politicalcompass.org people. And the particular statements which wind up in independent eigenvectors are interesting too: it's surprising, for instance, that the statement about sexual freedom doesn't appear high up in the eigenvector which describes (sort of) `authoritarianism'.
This raises a last issue to mention before I go to bed. Since these axes are picked out of the data by an automatic statistical procedure, we don't `know' what they mean. Above, I've tried to attach some clichéd labels to them; others might disagree with the words I've used, and in any case it doesn't really mean anything to say that person X is 0.73 `authoritarian' while person Y scores only 0.57. (Well, it might tell me whether I'd want to share a house with them....)
In order to give the results some context, what I want to do is copy the politicalcompass.org people in guessing the answers which would be given by famous politicians, and then show respondents where their answers place them relative to those notable people. I've started work on this, but it's actually quite difficult, since to do this honestly requires a fair amount of research. I may try sending the survey to actual honest-to-goodness political celebrities -- probably those who are somewhere between retirement and senility, if I want there to be any significant chance they'll respond -- so that I can get some results straight from the horses' mouths. I don't know how successful that's likely to be. I'd also appreciate if anyone who is intimately familiar with the programmes of the UK's various political parties would tell me how Manifesto Man (or Woman) -- the imaginary person who has swallowed whole and taken to heart that party's entire set of policies -- would respond. That would allow me to show where people lie in relation to the individual parties, too.
More link propagation
Francis Irving and Julian Todd are working on an interesting project called The Public Whip, a site which digs through Hansard to produce a searchable database of how each MP votes (and, in particular, how often they rebel against their party whip -- hence the name). Also interesting is their clustering of MPs.