
I promised more on the estimation quiz, and here it is -- better late than never, I hope. (This probably won't make much sense unless you read the first bit published on Saturday. Ignore the bit where I promised that this article would be published last Sunday.)
First a note on the scoring. Here is the distribution of scores achieved by the first five-thousand-odd respondents:
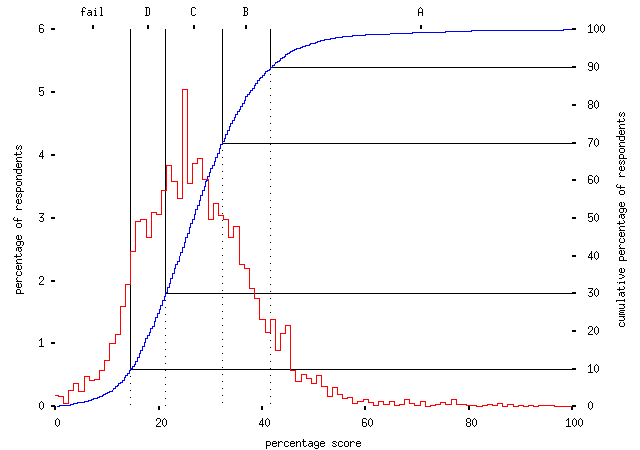
As a vague attempt to cash in on the traditional summer obsession with exam grades, I've made up some mark boundaries, too. Grading `on the curve', with 10% achieving an A, 20% a B, 40% a C, 20% a D, and the remainer failing, the grades are:
| Grade | Score (%) |
|---|---|
| fail | < 15 |
| D | < 21 |
| C | < 32 |
| B | < 42 |
| A | all others |
In the tradition of GCSEs, I could also award an A* grade for those who scored ooh, let's say, 70% or more, but I suspect most who did were cheating, so why bother?
(This explains the fairly low scores achieved by various well-informed people who answered the thing....)
I should say something about how the scores are computed, too. As I've said before, the algorithm is very ad-hoc. I wanted the scoring algorithm to:
- give an individual score for each question;
- give the maximum possible score for each question when the respondent's answer was exactly correct (including any actual error on the answer);
- give the minimum possible score for each question when the respondent's answer was claimed to be exact (uncertainty of zero) but was not correct; and
- otherwise reward accurate answers (close to the true answer) and realistic uncertainties (close to the difference between true answer and answer given), trading the two off in a reasonable fashion.
I spent ages looking for a mathematically satisfying formula for this and didn't find one. In the end I used the following for each question, where x and dx are the candidate's answer and uncertainty, and X and dX are the true answer and uncertainty: (yet again we suffer from the `HTML not being any good for maths' problem)
s² = dx² + dX²
m = x unless x = 0, in which case m = X
p = max(1 - |dx-dX| / m, 0)
score = 10 p exp( -(x-X)² / 2s²)
-- the idea here being that we give a score based on (something like) the probability of the true answer given the normal distribution implied by the given answer and uncertainty, with a penalty function which increases with the departure of the claimed uncertainty from the true error. The 10 is just there to make the score on each question a convenient integer.
There's one further hack, which is that if the question asks for a date, the answers are converted into years-before-the-present. This is so that the penalty function (which compares given uncertainties with absolute answers) is reasonable in that case, the argument being that our knowledge of the past is likely to become more uncertain the further back we go. Obviously this doesn't really work with the question on the date of birth of Christ.
On the whole, this scoring system is rubbish. Note in particular that if your uncertainty is as large as your answer, you will get zero, which hardly rewards accurate estimation of uncertainties!
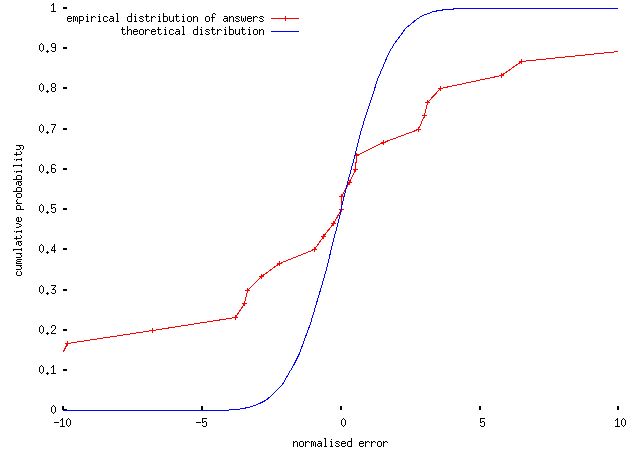
Various commenters, including Andrew Cooke on Crooked Timber, and John Quiggin commenting on my last piece here, pointed out that a better approach might be to base scores on properties of the distribution of each respondents' relative errors, y = (x-X)/dx. The idea is that, if a person is good at estimating, their uncertainties should be equal to the true errors and there shouldn't be any overall bias in whether their answers are above or below the true answers (since the questions are all on different topics). In this case, y should be distributed with mean zero and variance one. This looks like a fairly reasonable way to assess scores, in fact; for instance, here are the distributions for someone who didn't do very well (score 18%):
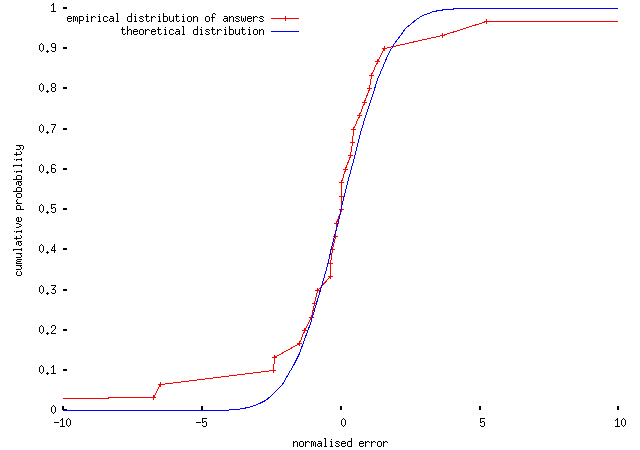
and for someone who did rather better (42%):
One way to compare the distributions (by no means the best, but I'm lazy and it's easy to compute) is the Kolmogorov-Smirnov statistic (the largest absolute difference between the two cumulative distributions); this is pretty well correlated with the ad-hoc scores I've computed:
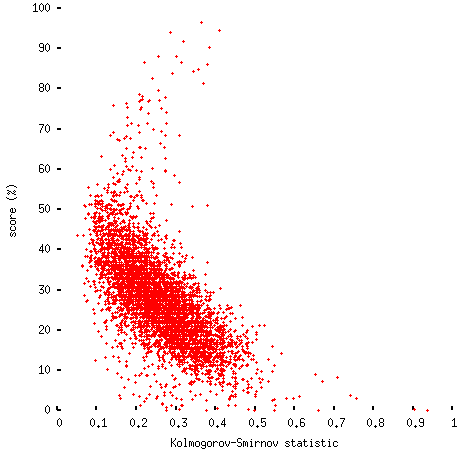
(Ignoring the tail that runs up to the top left, which consists mainly of people who did so well they were probably cheating, a linear model explains about 50% of the variance, which isn't too bad.)
So, next time anyone designs one of these quizzes, I'd suggest more work on the scoring algorithm along these lines. One problem with schemes based on the distribution of answers is that they can't really give a score to each answer, which could make the game a bit unsatisfying, but that's probably not a disastrous problem.
Anyway, this is a bit off-topic. The real ulterior motive of the quiz was to test the theory that people who are incompetent in a given field are also lousy at estimating their own competence. I wanted to see whether the respondents who gave the poorest answers to the estimation questions were also likely to give unreasonably narrow uncertainties.
It turns out that they don't. The uncertainties given tended to be more-or-less reasonable estimates of uncertainties. The distribution of uncertainties relative to actual errors is peaked around 1:
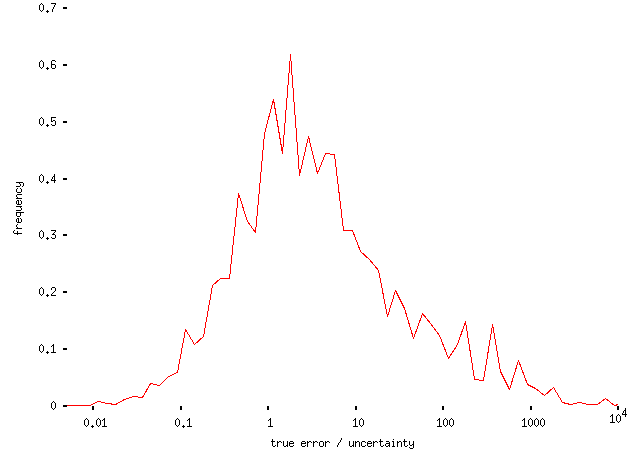
and looking at individual questions typically gives something like this: (in this example, for the question about the distance from the earth to the moon)
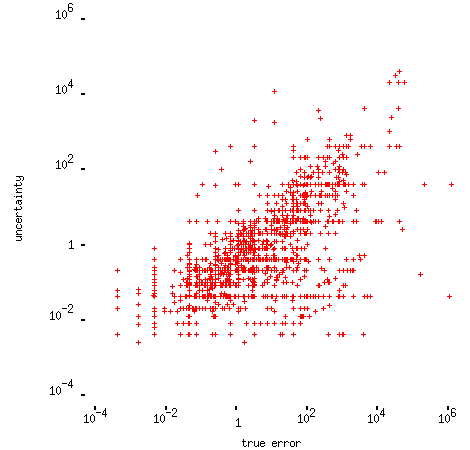
-- that is, people who gave inaccurate answers typically gave large uncertainties too. (Actually the results for some of the questions look much more complicated than that, but that's mostly because of `round number' effects, as far as I can tell.)
This probably isn't a very good test of the `incompetent and unaware of it' theory, but still, it restored my faith in humanity a bit. (I mentioned this result to a friend of mine, and he replied, ``That's disappointing.'' And then, after a pause, ``I suppose it isn't, actually.'' Which more-or-less sums it up.)