{kind=link}

Here's a lovely statistic from The International Atomic Energy Agency's site about the tsetse fly:
African sleeping sickness affects as many as 500,000 people, 80 percent of whom eventually die, ....
Errm. Only 80 percent? Cf. this article....
Yesterday I went to a talk by a chap called Nick Craswell, from CSIRO (the Commonwealth Scientific and Industrial Research Organisaton, sometimes `backronymed' as `Counting Sheep In Remote Outback'), titled ``There's something about Google: Query-independent evidence in web search.'' Craswell had, apparently, given the talk at Google a short while before, though it wasn't quite clear how it was received.
Query-independent evidence, obviously enough, just means measures which are calculated over documents rather than over queries. On the web, query-independent evidence often takes the form of metrics calculated on the graph of links between pages; well-known examples are Google's PageRank and Kleinberg's HITS. The information-retrieval (IR) community apparently doesn't think much of query-independent evidence, which leaves them in a bit of a bind when it comes to explaining how it is that search engines like Google work so well. (Craswell recounted that users of search facilities he'd been involved in developing complained that it didn't return results which were enough like Google's....) Instead, the IR people prefer to use only measures of `relevance'; that is, the quality of the match between the query and document text.
One argument for why Google is a more useful search engine is that it tends to return home pages. How does it do this? The normal argument is that measures like PageRank favour pages with `authority' -- that is, those which are heavily linked; home pages tend to be heavily linked-to. Actually, it turns out that in a slightly contrived home-page finding exercise it's sufficient to bias search results in favour of short URLs, but this isn't good enough for real use.
To investigate these ideas further, Craswell decided to try learning from `resource lists'; that is, data from directories such as Yahoo or DMOZ. The idea here was to compare the results of a conventional search engine on some corpus with the pages listed for that topic by a human editor, on the basis that the human-listed pages would be in some sense the most useful. Further, it can probably be assumed that the audiences for a directory service is similar to that for a search engine.
These experiments were done with a few million pages from the US and Australian governments, and some more from Australian and UK research sites; the directory data were taken from Yahoo and DMOZ. Out of about a million US government pages, about 2,000 were listed in the directories.
The results of the experiments were essentially that, by ranking search results by a linear combination of some query-independent rating and the results of the standard BM25 relevance measurement, it's possible to push the human-chosen sites from the directory up to the top of the search results. URL depth (number of dots in host name or number of elements in the path or the sum of both) doesn't work tremendously well, but URL length (in characters) works OK. (One interesting result was that short host names in .gov tended to be better results than long ones, but long host names in .ac.uk were better than short; this probably isn't very surprising when you think about it....)
Link-based methods worked better; Craswell showed two, one of which was simply `indegree' (number of links to this page from other pages in the corpus), and the other was some secret technology which he didn't tell us -- or Google -- about. Of course, on limited corpora like these, there was no need to worry about `spamming' of the search engine results, so Craswell was able to claim that indegree and PageRank were approximately equally useful measures. This is certainly not the real world!
The best results were obtained with about 75% weighting to BM25 and 25% to the link-counting measure; or with about 8% BM25 and 92% URL-length. The idea of choosing these weightings based on how specific -- or, easier, how long -- the query is, was also raised. The idea being that if I search for ``Microsoft' I probably want a highly-linked page such as the Microsoft home page, whereas if I search for something really detailed about an API call or application bug, I need a specific page, probably deep on the Microsoft site, which isn't likely to be highly linked-to. (One thing I notice about Google is that, for rather specific queries, it likes to return postings from archived mailing lists. I don't know whether this is because mailing list archives are heavily cross-linked, or simply because a substantial fraction of the technical discourse on the web is contained in mailing list archives....)
So, anyway, this was all very interesting. It's not really clear that it's useful or relevant, though. One thing to bear in mind is that lists like those on Yahoo or DMOZ are mostly compiled by human editors using Google anyway, so it probably shouldn't come as too much of a shock that a search engine which replicates some of the features of Google scores those pages highly. Another problem is that it's not really clear that the sites listed on directories are actually that useful; they're good for finding home pages, but for really specific queries, they're not typically very helpful. 'Course, it would have been a little blatant to try to match the experimental results against those that Google gives. The whole talk seemed to be a bit of an apologia for the conventional views held by the IR community: ``we have demonstrated that these techniques aren't any good, so how is it that they work so well in reality?''
I've just noticed the caption at the top of the Weblogs.Com front page:
Welcome to the meeting place for blogging excellence on the Internet. Any weblog can participate.
-- am I the only person to spot the contradiction?
Oh dear. It seems that Eric S. Raymond has fallen off the deep end; first fetchmail, and now this: a noxious screed advocating shooting police officers.
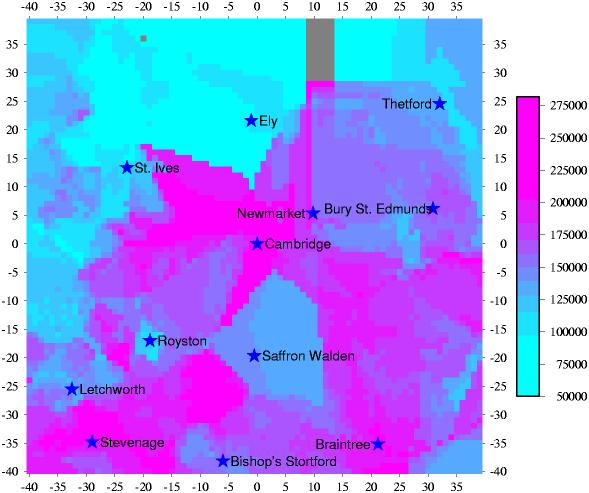
A silly idea: take the adverts for houses for sale which streetmap.co.uk (or, rather, its partner SoldIt) displays on each map page, find the average price in each region, and plot it up on a map, like this one.
There are some serious problems with this approach (in particular with the data quality). Drop me a line if you want a copy of the code to play with, anyway.
I went to see Michael Moore's Bowling for Columbine, which was excellent: amusing and shocking by turns. I didn't even find the dénouement, doorstepping Charlton Heston, particularly offensive, as others did: sure, it was cringe-worthy, and it's clear that Heston isn't quite with it (the camera lingers on his hand, reaching out to steady himself on a doorframe as he leaves the room; very sad). But this is a man who keeps numerous loaded guns in his heavily-guarded Los Angeles home; a man who sees nothing wrong with holding NRA gun rallies immediately after school shootings. The man needs the piss taken out of him, frankly, even if he is dying of Alzheimer's.
The central question of the film -- why are there 11,000 firearm-related deaths per annum in the United States, and nothing like that number in other rich countries even where there is extensive gun ownership, as in Canada? -- is fascinating. I wish I knew the answer.
It's odd that Moore's film works so well, since his book is a pretty poor effort: not very well researched, and a rather thin and ill-thought out rant all over (the web site isn't any good either -- ``text goes here''?) In particular his opinions on foreign affairs are pretty puerile, and he doesn't really offer any coherent-sounding solutions.
Moore doesn't come across as a very intellectually honest person. An example from his film: he visits the Lockheed-Martin factory in Littleton, Colorado, and links the fact that a weapons manufacturer operates in Littleton with the fact that a school shooting occured there at Columbine High School. There is much footage of rockets being assembled, and of excellent workplace banners (``Our goal is to be 100% foreign object free.'') OK, fair enough; but Moore implies again and again that this is a missile factory. It isn't. It makes space launchers. That's sloppy, and doesn't do much for his rather flimsy argument that indiscriminate US military intervention overseas makes the US population more disposed to shoot one another. (Though he does get some choice quotes from the Lockheed-Martin PR drone.)
Has it occurred to anyone that if we train squaddies to operate modern fire engines, they might demand to be paid £30,000 per annum, just like firemen want, rather than the £12,000 to £15,000-odd they get currently?
This is the most surreal spam I've received in, oh, weeks. It must have been done with Babel Fish or its equivalent. I particularly like `our hand of working is well mais cockroach', though I'm at a loss as to what it might mean....
Good Morning !
Dear Mr,
Are one company Brazilian located of Florianópolis -- SC, dispose now of 65 web designers and with big experience in the elaboration of Web Sites. Like of learning if exists to possibility to have one organization and will develop some projects for yours company, being that our hand of working is well mais cockroach and dispose of one great team prepared and with softwares and hardwares of last generation.
Without more, await contact.
Att.
Luís Cláudio R. do Prado clik@clikbrasil.com.br Fone/fax: ou fax 51 (2148) 259-5003 / 9958-8544
We can only assume that this chap doesn't know my views on web design.
I went to a talk about Microsoft's Palladium initiative by John DeTreville (no home page) of Microsoft Research Redmond. Interesting stuff, and it left me unhopeful for the future. I wrote up some notes and impressions for the CDR mailing list.
I also seem to have taken on responsibility for the CDR FAQ -- let's hope it's not too much work....
How bread is made. With a scary flow diagram. Is it any surprise that sliced bread tastes so plastic?
This is all done with wwwitter.
Copyright (c) Chris Lightfoot; available under a Creative Commons License. Comments, if any, copyright (c) contributors and available under the same license.
Hosted and supported by